Serialization - What to choose?.
August 9, 2014 . Comments
Tags: java, serialization
Serialization of objects impacts the performance of a service considerably. The response time for receiving/sending objects is directly linked to the time taken for serialization and deserialization. If the serialized bytes are more that impacts the time spent on the wire. The key to choose the right technology should be based on 3 factors no loss of data, serialization byte size and time taken for serialization and deserialization.

Serialization is the process of converting the object in memory into a byte or char stream so that it can be saved to disk or sent over the wire.
Deserialization is the process of converting a byte stream or char stream into objects.
There are two design decision we need to take while choosing the right format.
We choose byte stream to reduce the size of the object or because that is the default supported by the programming language out of the box. When we want to consider performance byte stream would be the first choice. Java Serialization will defenitely not be the right serialization platform to use as it is very slow and very descriptive.
There are many choices to make in order to pick the right serialization API other than java serialization.
Google Protobuf
Google's protobuf is extremely fast.
The way it works is by generating a custom serialization class for the object. It writes a number for each type that is serialized and the value. Hence considerbly reducing the type information that is written. The binary stream written by protobuf is propereitary you will have to use the same objects builder to de-serialize the object back. Protobuf is very ideal as it supports for C++, java and other languages as you can use the same protoc compiler to generate the language specific code to serialize/deserialize the objects.
Major disadvantage is, it cannot support Generic object types or deep objects like Map in a class. This makes it not suitable or would put more work on the client and server API to convert the generic objects into strong typed objects for protobuf serialization.
GSON and others
There are other fast binary serializtion API's like GSON in the market. These seem to mitigate the problem Protobuf has by allowing the developer to register the class before serializing it. Still we will have to write a general object serializer for the class of type Map. This makes it difficult for serializing deep objects. Our externalization code becomes very difficult. It would be better to write my own instead of using a generic serializer specific for a framework like GSON or simple jackson. Provided i can meet the performance of either of them.
Fast Serialization
The idea behind fast serialization is impressive. Some of the impressive features of fast serialization are
- It is a drop in replacement for java serialization and is only slightly slower than protobuf (meassured in terms of under seconds ).
- It has class preregistered for all basic objects, types and array combination.
- Does convert boxed objects like Long into primitive type of long while serializing.
- Only stores the actual allocated size for a primitive type. For ex:- if you define a type as long and its actual value is 123 it only uses 2 bytes allocation to serialize it , 1 byte for storing the type and 1 for the actual value of 123.
- Repetitive strings in object are serialized and written once naturally allowing for compression.
- Most strings in the north american or the europian subcontinent fall within the 254 charectar mark. But we use UTF-8 as the charecter set to store them - which makes it as using 2 bytes for every char. FST uses 1 byte to store all char types and uses 3 bytes for any occassional double byte char.
It almost felt like some one read my mind today and went back in time to write it ;). The data being compressed using this is smaller in size than protobuf and almost the same size or even better than lz4 compression with more speed.
It is not fair if i don't mention the disadvantages even though i like it a lot. The developer uses UnSafe methods to acheive the speed of serialization. I am trying to push its limits. It is working in a fantastic way when trying to serialize and de-serialize objects of size less than 2 MB which is 10 times bigger in size when using java serialization. Performance degradation is seen when the object size goes higher, it is still able to serialize and deserialize within times lesser than java serialization.
Let us look at some code to see how easy it is to use FSTSerialization
Serialization Code
De-Serialization Code
In the above example the same set of bytes are used for serialization as well as de-serialization so constant known stress for GC.
Some metrics while doing serialization and deserialization between client and server on the same machine using FST and Banyan random rows fetch. The data size is in the low 1k range and doesnot include network traffic time. This should give you an idea about the speed of doing search operations in Banyan.
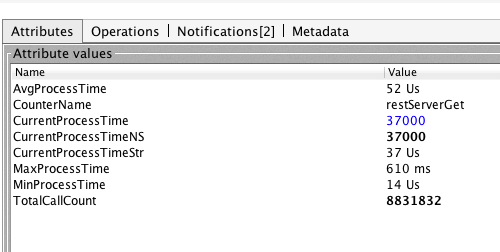
The max processing time is because of my MAC crying and saying not enough memory.
The char stream way of serialization is slow as they are either verbose or evrything is converted into double byte strings. Any soultion using char stream opposed to byte stream will be atleast two time slower for simple array copy and network buffer transfer as char in java uses double byte by default.
XML XML is usually too verbose as it has to have start and end tags along with the name and value attributes to make it readable. Also to store in xml we will have to escape the escase chars makes the string manipulation on large blobs very slow, considering that strings are immutable in java. It is simple to read follows a strong schema and it also incurs the cost of validation of input as the different types could have garbage values and type mismaches. Easy for other languages to support.
JSON Much simpler than XML and very easy to read. Too less of a charectars to escape. Easy for other languages to support. Can be represented in a huge hashmap lke object type as it needs the Key and value pair combination to mostly make it readable. This also is verbose but less than XML. Time taken for serialization and deserialization is less but considerable higher than binary format. Easy for other languages to support.
Table When trying to read or write tabular data it is a fair choice to choose this format, where the first row is the columns and consecutive rows are values. It is way simpler than the above two to interpret. The disadvantage is not all the data we read and write is tabular in format. If choosing CSV or tab it is easier for other languages to support.
Conclusion I am thinking of using a combination of the three to support a wide range of audience. To start with to give a rock solid product, I can use Fast Serialization with binary stream and later while developing admin tools can have support for tabular for single row and multi row select from singe table and JSON while trying to select graph data. This would make php and javascript client's happy.
Disclaimer The suggestions provided are suitable for Banyan and should not be considered as a defacto for all applications.
Feel free to comment on the post but keep it clean and on topic.